珞珈村下山 每天前进一小步
集成学习(Ensemble learning)相关理论
Written on November 7th, 2016 by jian11
Author: Dr. Robi Polikar, Rowan University
集成学习是由多个模型(如分类器或专家)策略性地生成和组合以解决特定计算性的智能问题的过程。集成学习主要用于改进模型(分类,预测,函数近似等)的性能,或者减少不良选择变为现实的可能性。集成学习的其他应用包括为模型做出的决策分配置信度,选择最优(或接近最优)特征(feature),数据融合(data fusion),增量学习(incremental learning),非平稳学习(nonstationary learning )和错误校正(error-correcting)。本文着重于集成学习在分类问题的相关应用,然而,下面描述的所有原理思想都可以容易地推广到函数近似或预测类型问题。
1. 引言
基于集成的系统是通过结合不同的模型(以下简称分类器)获得的。因此,这种系统也被称为多分类器系统,或者仅仅称为集成系统。使用基于集成的系统具有统计意义有几种情况,这将在下面详细讨论。为了充分和实际的体会使用多个分类系统的重要性,我们举了一个可能从心理学背景而不是从统计学意义上来说更加可靠的论据:我们在日常生活中做一个决定前通常会询问多个专家(expert)的意见。例如,我们通常会在同意医疗程序之前询问几个医生的意见,我们在购买商品(特别是大额商品)之前阅读用户的评论,我们通过检查他们的参考资料来评估未来的员工。事实上,即使是这篇文章也是由几个专家审查后才被许可出版的。在每一种情况下,最后的决定也是由几个专家的个人决定组合而成的。在此过程中,首要目标是尽量减少不必要的医疗程序,低劣的产品,不合格的员工,甚至是一篇写得不好、具有误导性的文章。
1.1 模型选择(Model Selection)
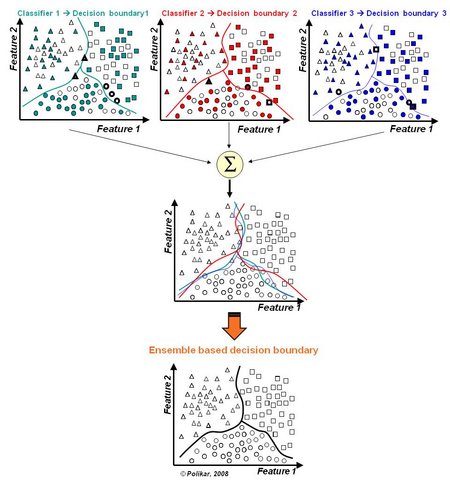
这可能是为什么在实践中使用基于集成的系统的主要原因:对于给定的分类问题,什么才是最合适的分类器?这个问题可以用两种不同的方式解释:i)在多个竞争模型中应该选择什么类型的分类器,比如多层感知器(MLP),支持向量机(SVM),决策树,朴素贝叶斯分类器等; ii)给定特定分类算法,应该选择该算法的哪种实现形式。比如,MLP的不同初始化值可以产生不同的判定边界,即使所有其他参数保持不变。我们最常用的方法,在训练数据上选择具有最小误差的分类器,是一个有缺陷的方法。对训练数据集的性能 - 即使使用交叉验证方法计算 - 在对以前看不见的数据的分类性能方面可能是误导。训练数据所表现出的特征可能对于之前未知的数据(validation set)在分类性能上具有误导,即使采用了交叉验证。然后,在具有与验证数据(用于评估分类器性能的一部分未用的训练数据)所计算的相同(伪)泛化性能(generalization performance)或甚至是相同训练的所有(可能无限)分类器中,我们应该选择哪个?一切都是等可能的,人们可能会随意选择,但是这种决定带来了选择特别差的模型的风险。使用这样的模型的组合,而不是只选择一个,并且通过比如简单地对它们求平均值来组合它们的输出结果,可以降低不幸地选择到特别差的分类器的风险。需要强调的是,我们不能保证多个分类器的组合始终比运行组合中单个分类器的效果要好。除了某些特殊情况(Fumera 2005)之外,组合平均性能的改善和提高是能够被保证的。因此,集成分类器可能不一定会优于集合中的最佳分类器的性能,但它肯定减少了做出最差选择的整体风险。 为了使这个过程有效,就像本文后面更详细描述的那样,各个专家必须在它们之间展现出一定程度的多样性。在分类内容中,分类器中的多样性(通常通过对每个分类器使用不同的训练参数来实现)允许单个分类器生成不同的决策边界。如果实现适当的多样性,每个分类器产生不同的误差,则其策略性的组合可以减少总误差。 图1形象的展示出了这种概念,其中在可用训练数据的不同子集上训练的每个分类器产生不同的错误(显示为具有黑色边界的实例),但是(三个)分类器的组合提供了最好的决策边界。
1.2 过多或过少的数据(Too much or too little data)
基于集成的系统在处理大量数据或缺乏足够的数据时可能非常有用。当训练数据的量太大而使单个分类器训练十分困难时,可以将数据策略性地划分成更小的子集。然后每个子集可以用于训练单独的分类器,然后可以使用适当的组合规则(见下面不同的组合规则)进行组合。另一方面,如果数据量太少,则可以采用bootstrapping方法,使用数据的不同bootstap samples(不放回抽样)来训练不同的分类器,其中每个被抽取的自举样本(bootstrap sample)是用于替换原本数据的随机样本,并且是从底层分布(underlying distibution)(Efron 1979)中独立抽取的。
1.3 分而治之(Divide and Conquer)
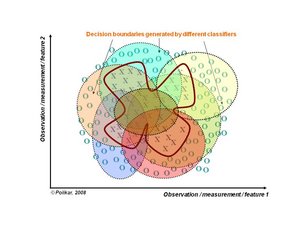
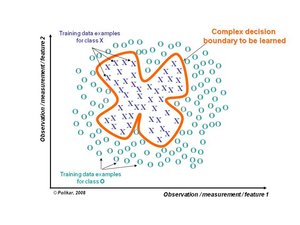
某些问题对于给定的分类器来说太难了。 事实上,将数据与不同类分开的决策边界可能太复杂,或者位于可以由所选择的分类器模型实现的函数能力之外。考虑图2中描述的具有复杂判定边界的二维,两级问题。线性分类器可以学习线性边界,而不能学习这个复杂的非线性边界。然而,这样的线性分类器的适当组合所形成的集合却可以学习任何非线性边界。举个例子,假设我们有一个可以产生圆形边界的分类模型,这样的分类器不能学习图2所示的边界。现在思考一个由图3所示的分类器的组合所产生的圆形决策边界的集合,其中每个分类器基于实例落在其边界内还是边界外来将数据标记为O或者X,基于足够数量这种分类器的多数表决的决策,可以很容易地学习这个复杂的非圆形边界(受制于以下几点:
- 每个分类器的输出是独立的
- 至少一半的分类器能够正确地分类一个实例
参见基于投票的组合规则的证明以及这种方法的详细分析有关的讨论)。在某种意义上,分类系统遵循分治算法,通过将数据空间划分为更小和更容易学习的分区,其中每个分类器仅学习更简单的分区之一。然后底层复杂的决策边界可以通过不同分类器的适当组合来近似。
1.4 数据融合(Data Fusion)
在许多要求自动决策的应用中,接收从不同来源获得的包含各种补充信息的数据并不罕见。这种信息的适当的组合被称为数据融合或信息融合,并能相比基于任何的单独数据源的决策会提高分类器的决策精度。例如,为了诊断神经障碍,神经科医师可以使用脑电图(一维时间序列数据),磁共振成像(MRI),功能性MRI或正电子发射计算机断层扫描(PET)扫描包括图像(二维空间数据),脑脊液中的某些化学物质的数量以及受试者人口统计学指标,例如年龄,性别,受试者的教育水平等(标量或分类值)。这些异质特征不能一起用于训练单个分类器(并且即使它们可以通过将所有特征转换为标量值的向量,这样的训练也不可能成功)。在这种情况下,可以使用多个分类器的组合(Parikh 2007),其中单独的分类器在每个特征集上独立地训练。然后可以通过下面描述的任何组合规则来组合由每个分类器做出的决定。
1.5 置信估计(Confidence Estimation)
基于集成的系统的非常结构自然地允许对由这样的系统作出的决定分配置信度。 考虑到在一个分类问题上有多个分类器训练的结果。如果绝大多数分类器与他们的决定一致,则这样的结果可以被解释为这个集合在其决定中具有高置信度。然而,如果一半的分类器做出一个决定,另一半做出不同的决定,则这可以被解释为这个集合在其决定中具有低置信度。应当注意的是,集合在其决策中具有高置信度并不意味着决策是正确的,反过来,以低置信度作出的决策不一定是错误的。然而,已经证明的是,如果适当训练的集合决策的置信度高,则其通常是正确的,如果其置信度低,则通常是不正确的。使用这样的方法,集成决策可以用于估计分类决策的后验概率(Muhlbaier 2005)。
1.6 使用集成系统的其他原因(Other Reasons for Using Ensemble System)
在2000年的评论文章中,Dietterich列出了使用基于集成的系统的三个主要原因(Dietterich 2000):
- i)统计上的(statistical);
- ii)计算上的(computional);
- iii)代表性的(representational)。
我们注意到这些原因与我们在上面列出的原因有些类似。统计原因是缺乏足够的数据来正确表示数据分布; 计算的原因是模型选择问题,其中许多模型可以解决给定的问题,我们应该选择哪一个。 最后,表示原因是为了解决所选择的模型不能正确地表示所寻求的决策边界的情况,这在上面的分而治之部分讨论。
2. 历史
或许在集成学习系统方面做出最初探索的就是Dasarathy和 Sheela在1979年的论文(Dasarathy 1979),他们最早提出了在分而治之的思想下使用集成系统,使用两个或者更多的分类器分割特征空间。十多年后,Hansen和Salamon(Hansen 1990)展示了集成系统方差缩减的特性,使用类似配置的神经网络的集成系统可以提高神经网络的总体性能。但是,Schapire的工作将集成系统置于机器学习研究的中心,因为他证明了通过称为增强(boosting)的过程组合弱分类器可以产生概率近似正确(PAC)意义上的强分类器(Schapire 1990)。Boosting是AdaBoost算法系列的前身 - 它可以说是近来最流行的机器学习算法之一。 从这些开创性作品出现以来,集成系统的研究迅速扩张,许多创意名称和想法在文献中经常出现。这份长长的清单包括复合分类器系统(composite classifier systems,Dasarathy 1979),专家混合(mixture of experts,Jacobs 1991&Jordan 1994),堆积泛化(stacked generalization,Wolpert 1992),多个分类器的组合(combination of multiple classifiers,Ho 1994&Rogova 1994&Lam 1995&Woods 1997),动态分类器选择(dynamic classifier selection,Woods 1997),分类器融合(classifier fusion ,Cho 1995&Kuncheva 2001),分类器集合(classifier ensembles)等等。这些方法主要存在两个方面的不同:i)用于生成个体分类器的特定过程; ii)用于组合分类器的策略。 集成系统也可以基于是否选择或融合分类器来分类(Woods 1997,Kuncheva 2001,Kuncheva 2002,Ho 2000):在分类器选择中,每个分类器被训练成在特征空间的一些局部区域中成为专家(如图3)。然后,分类器的组合是基于给定的实例:根据一些距离度量用最接近实例的数据训练出来的分类器被给予最高置信度。一个或多个局部专家可以被提名出来作出决定(Jacobs 1991,Woods 1997,Alpaydin 1996,Giacinto 2001)。在分类器融合中,所有分类器在整个特征空间上训练。 在这种情况下,分类器组合涉及合并个体(通常较弱的和/或多样的)分类器以获得具有优越性能的单个(更强的)专家。 这种方法的例子包括袋装预测器(bagging predictors,Breiman 1996),增强(boosting,Schapire 1990),AdaBoost(Freund 2001)及其许多变化。该组合可能只适用于分类标签,或适用于个别专家的特定类别的连续值输出(Kittler 1998)。 在后一种情况下,分类器输出通常被归一化为[0,1]间隔,并且这些值被解释为由分类器给每个类的支持度,或者作为类条件后验概率(posterior probabilities)。 这种解释允许通过代数组合规则(多数投票,最大/最小/和/积或后验概率的其他组合)形成一个集合(Kittler 1998,Kuncheva 2002,Roli 2002),模糊积分(fuzzy integral,Cho 1995),Dempster-Shafer (Rogova 1994),以及最近的决策模板(Kuncheva 2001)。关于分类器集成的大量文献的样本可以在Kuncheva的最近的书(Kuncheva 2005)中找到,第一篇致力于基于集成分类器的理论和实现的文章,以及其中的参考文献。由本文的作者撰写的两个最近的教程还提供了集成系统的综合概述(Polikar 2006,Polikar 2007)。
3. 多样性(Diversity)
集成系统的成功与否,即其校正其成员错误的能力,完全取决于组成整体的分类器的多样性。毕竟,如果所有分类器提供相同的输出,纠正可能存在的错误是无法实现的。因此,集成系统中的各个分类器需要在不同的实例上产生不同的错误。直观的说就是,如果每个分类器产生不同的误差,那么这些分类器的策略组合就可以减少总误差,这个概念与噪声的低通滤波有点相似。具体来说,集成系统需要判决边界与其他分类器完全不同的分类器。这样的一组分类器才可以说是多样的,分类器多样性可以由多种方式实现。我们所期望的是,分类器输出应当是有条件的独立的,或者更好的,是负相关的。最流行的方法是使用不同的训练数据集来训练个体分类器。 这样的数据集通常通过重采样(re-sampling)技术获得,例如自举(bootstrapping)或装袋(bagging)(见下文),其中从整个训练数据中随机抽取训练数据子集,通常有替换()。为了充分确保各个边界不同,尽量使用基本相似的训练数据,较弱或不稳定的分类器被用作基本模型,因为它们可以产生足够多不同的判定边界,即便其对训练参数会产生小的干扰。 实现多样性的另一种方法是对不同的分类器使用不同的训练参数。 例如,可以通过使用不同的权重初始化,层/节点的数量,误差目标等来训练一系列多层感知器(MLP)神经网络。调整这样的参数能够控制各个分类器的不稳定性,并因此增强他们的多样性。 或者,也可以组合完全不同类型的分类器(例如MLP,决策树,最近邻分类器和支持向量机)来增加多样性。 最后,也可以通过使用不同的特征或者现有特征的不同子集来实现多样性。 事实上,使用随机特征子集生成不同的分类器称为随机子空间法(random subspace method)(Ho 1998),如本文后面所述。 关于对多样性问题的全面审查,见(Brown 2005)。
4. 常用的集成学习算法(Commonly used ensemble learning algorithms)
4.1 装袋(Bagging)
装袋算法(Bagging),又称引导聚集算法(Bootstrap aggregating),它是最早,最直观,也许也是最简单的基于集成的算法之一,具有惊人的良好性能(Breiman 1996)。装袋中分类器的多样性是通过使用训练数据的自举复制品来获得。也就是说,不同的训练数据子集是从整个训练数据集中随机抽取的(可替换)。每个训练数据子集用于训练相同类型的不同分类器。 然后通过对他们的决策进行简单多数投票来组合个体分类器。对于任何给定的实例,由大多数分类器选择的类就是是集合的决策。由于训练数据集可能存在实质上的重叠,因此可以使用额外的措施来增加多样性,例如使用训练数据的子集来训练每个分类器,或者使用相对弱的分类器(例如单层分类器(decision stumps))。 在图4中提供了Bagging的伪代码。

4.2 提升方法(Boosting)
与装袋类似,boosting也通过重新采样数据创建一个分类器集合,然后通过多数表决组合数据。不同的是,在boosting中,重新采样被策略性地安排以为每个后续的分类器提供最翔实的训练数据。实质上,Boosting的每次迭代创建三个弱分类器:用可用训练数据的随机子集训练第一分类器C1。在给定C1的情况下,选择训练数据最有信息的子集作为第二分类器C2。特别地,C2是用训练数据训练的,只有一半的训练数据能够被C1正确分类,另一半被错误分类。第三分类器C3用C1和C2都没有用过的实例训练。这三个分类器通过三方多数表决组合。 Boosting的伪代码和实现细节如图5所示。
